XGrammar
XGrammar is an open-source library for efficient, flexible, and portable structured generation. It supports general context-free grammar to enable a broad range of structures while bringing careful system optimizations to enable fast executions. XGrammar features a minimal and portable C++ backend that can be easily integrated into multiple environments and frameworks, and is co-designed with the LLM inference engine and enables zero-overhead structured generation in LLM inference.
Reference Paper
- Yixin Dong, Charlie F. Ruan, Yaxing Cai, Ruihang Lai, Ziyi Xu, Yilong Zhao, and Tianqi Chen. XGrammar: Flexible and Efficient Structured Generation Engine for Large Language Models. MLSys 2025.
Overview
XGrammar provides full and efficient support for context-free grammar in LLM structured generation through a series of optimizations. Our primary insight is that although we cannot precompute complete masks for infinitely many states of the pushdown automaton, a significant portion (usually more than 99%) of the tokens in the mask can be precomputed in advance. Thus we categorize the tokens into two sets:
- Context-independent tokens: tokens whose validity can be determined by only looking at the current position in the PDA and not the stack.
- Context-dependent tokens: tokens whose validity must be determined with the entire stack.
Figure 1 shows an example of context-dependent and context-independent tokens for a string rule in a PDA. In most cases, context-independent tokens make up the majority. We can precompute the validity of context-independent tokens for each position in the PDA and store them in the adaptive token mask cache. This process is known as grammar compilation.

At runtime, we retrieve the validity of context-independent tokens from the cache. We then efficiently execute the PDA to check the rest context-dependent tokens. By skipping checking the majority of tokens at runtime, we can significantly speed up mask generation. The figure below shows the overall workflow in XGrammar execution.
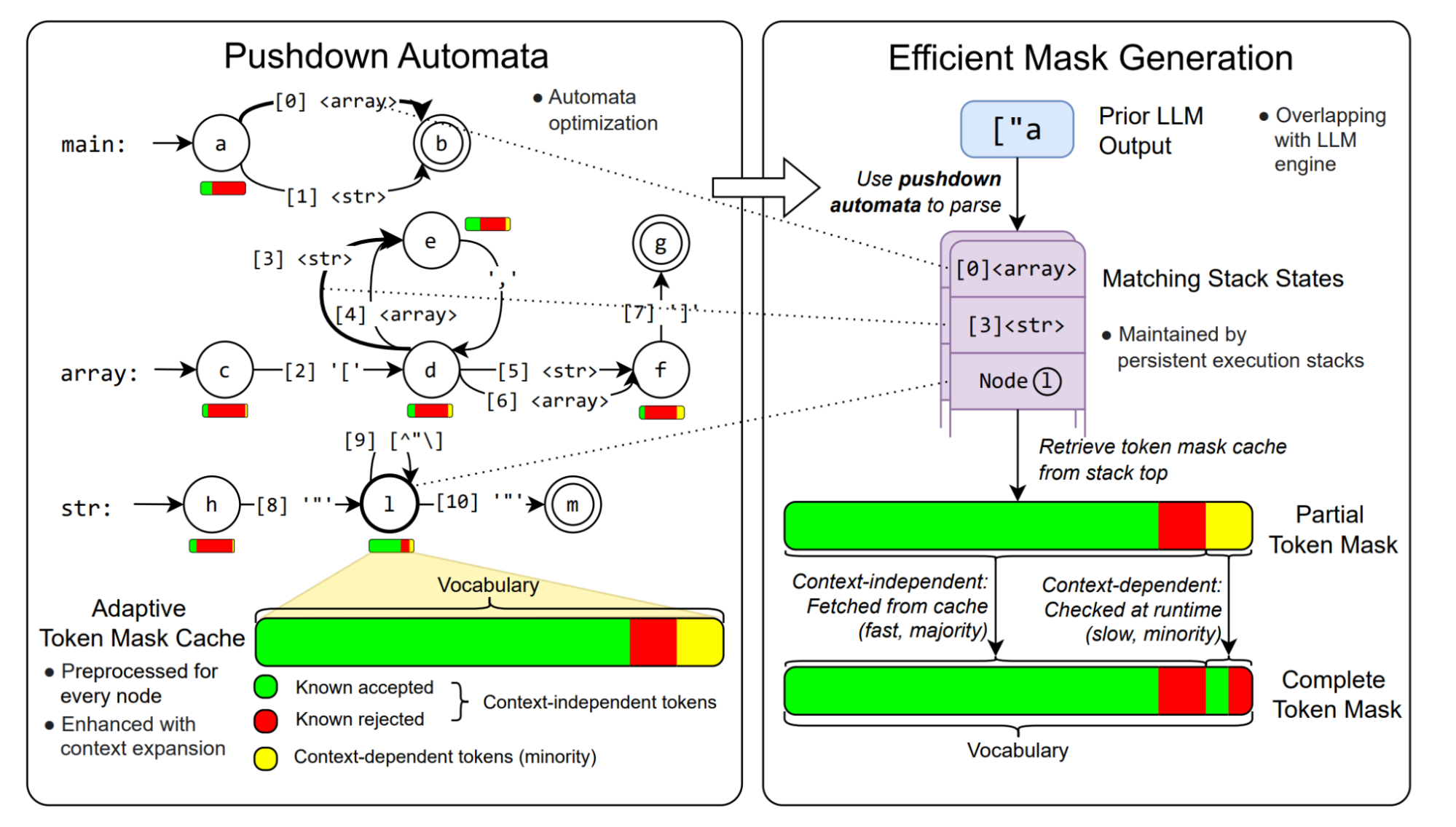
We designed an additional set of algorithms and system optimizations to further enhance the mask generation speed and reduce preprocessing time, summarized below:
- Context expansion. We detect additional context information for each rule in the grammar and use it to decrease the number of context-dependent tokens and further speed up the runtime check.
- Persistent execution stack. To speed up the maintenance of multiple parallel stacks during splitting and merging due to multiple possible expansion paths, we design a tree-based data structure that efficiently manages multiple stacks together. It can also store state from previous times and enable efficient state rollback, which speeds up the runtime checking of context-dependent tokens.
- Pushdown automata structure optimizations. We leverage a series of optimizations adopted from compiler techniques, particularly inlining and equivalent state merging to reduce the number of nodes in the pushdown automata, speeding up both the preprocessing phase and the runtime mask generation phase.
- Parallel grammar compilation. We parallelize the compilation of grammar using multiple CPU cores to further reduce the overall preprocessing time.
The above optimizations help us reduce the general overhead of grammar execution. Building on top of these optimizations, we further co-design the LLM inference engine with grammar execution by overlapping grammar processing with GPU computations in LLM inference.
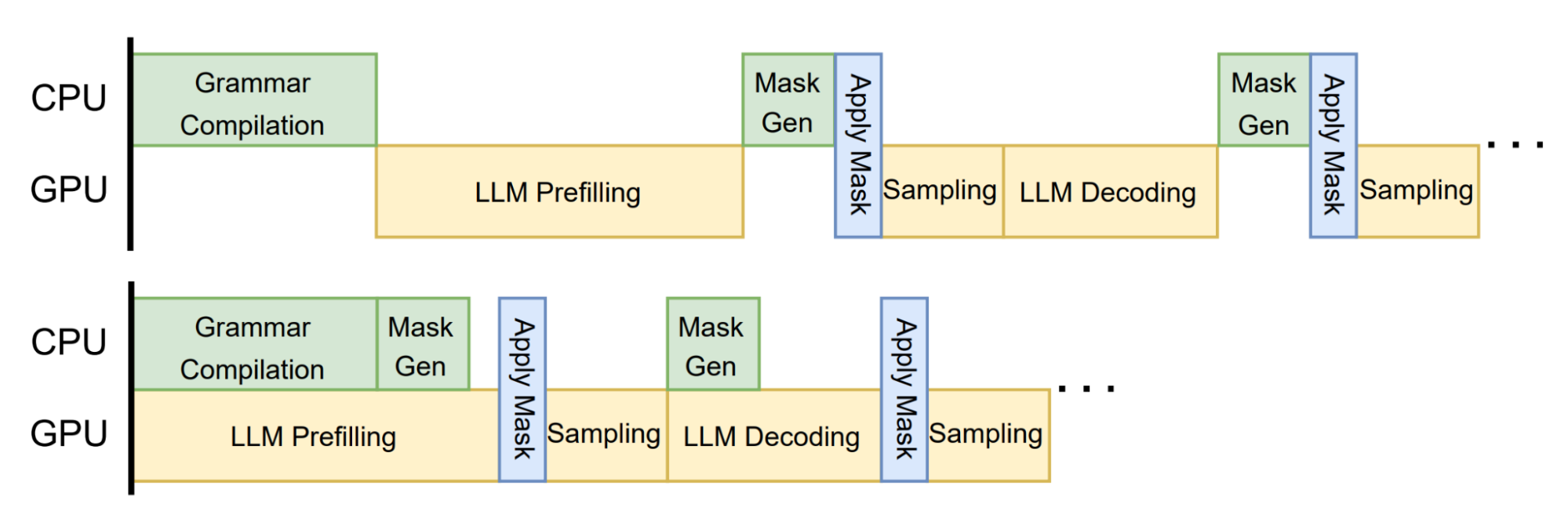
Figure 3 shows an example workflow that overlaps general grammar processing with LLM inference. We also provide additional co-design APIs, to enable rollback (needed for speculative decoding) and jump-forward decoding, which further speeds up the speed of structured generation. Through these optimizations, we achieve both accuracy and efficiency without compromise, fulfilling our goal of flexible and efficient structured generation.