TidalDecode

TidalDecode is a simple yet effective algorithm and system for fast and accurate LLM decoding through position persistent sparse attention. TidalDecode leverages the spatial coherence of tokens selected by existing sparse attention methods and introduces a few token selection layers that perform full attention to identify the tokens with the highest attention scores, while all other layers perform sparse attention with the pre-selected tokens. This design enables TidalDecode to substantially reduce the overhead of token selection for sparse attention without sacrificing the quality of the generated results.
Reference Paper
- Lijie Yang*, Zhihao Zhang*, Zhuofu Chen, Zikun Li, Zhihao Jia. TidalDecode: Fast and Accurate LLM Decoding with Position Persistent Sparse Attention. Preprint Arxiv.2410.05076
Technical Highlights
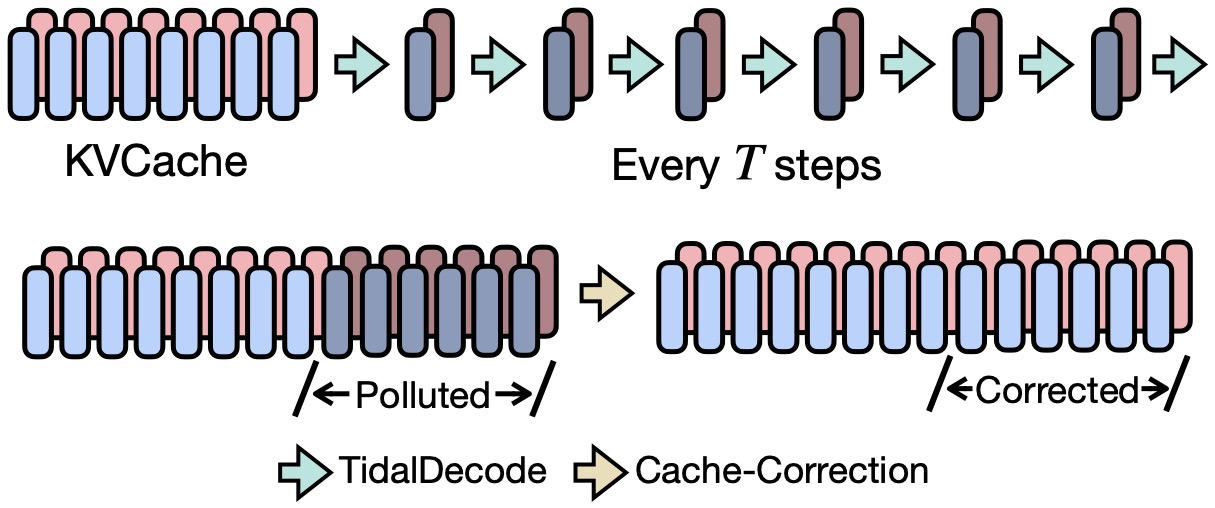
- Position Persistent Sparse Attention. A key insight behind TidalDecode is the observation that tokens chosen for sparse attention — based on their highest attention scores — exhibit significant overlap across consecutive Transformer layers within each decoding phase. Instead of independently selecting tokens for sparse attention at each layer, TidalDecode introduces a few token selection layers, which perform full attention to identify the tokens with the highest attention scores. All remaining layers implement position persistent sparse attention, where only the tokens selected by the token selection layers are retrieved from the KV cache for attention. Consequently, all other layers between two token selection layers operate on the same set of tokens, reducing the overhead of token selection.

- KV Cache Correction. For tokens decoded by sparse attention methods, their key/value representations can deviate from the original representation of full attention decoded ones, which we refer to as polluted tokens. The problem can be further exacerbated as their KV pairs are added to the KV cache, resulting in the error accumulation or distribution shift of the KV cache. This can lead to model performance drop in scenarios where the generation length is fairly long. To this end, TidalDecode uses a cache-correction mechanism to periodically correct the polluted tokens in the KV cache.
Evaluations
For all the evaluations, we only enabled Position Persistent Sparse Attention (with KV Cache Correction off) for a fair comparison. Experiments are conducted on a single Nvidia A100 (80 GB HBM, SXM4) with CUDA 12.2
- End-to-end Latency
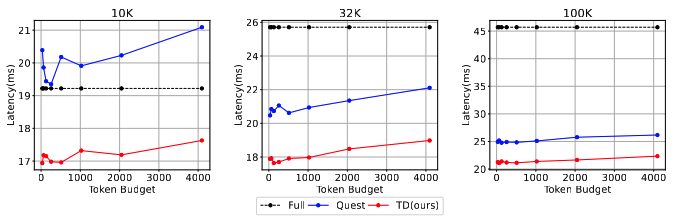
Figure 1: End-to-end latency results on LLaMA-2-7B model for Full attention baseline(Full), SOTA Quest, and TidalDecode(TD) when context length is 10K, 32K, and 100K, respectively.
- Attention Latency
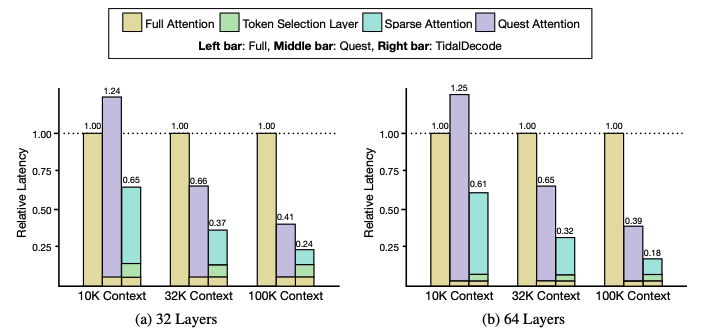
Figure 2: Overall attention latency results for different methods on the LLaMA model with (a) 32 and (b) 64 layers. The full attention model is used as a reference to show TidalDecode and Quest’s overall attention latency ratio. The left/middle/right bar denotes the full attention baseline, Quest, and TidalDecode, respectively.
- Accuracy
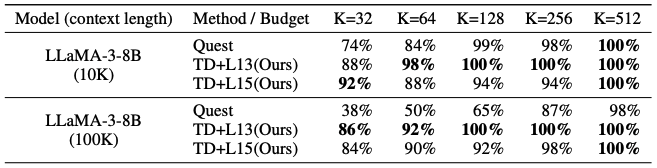
Figure 3: 10K- and 100K-context-length Needle-in-the-Haystack test results of TD+Lx (x means recomputing at Layer x) and Quest on Llama-3-8B-Instruct-Gradient-1048k. TidalDecode consistently outperforms Quest and achieves full accuracy with 128 tokens in 10K-, and 100K-context-length tests, which is only 1\% and 0.1\% of total input lengths, respectively.
Reference
If you are interested in TidalDecode and want to use it in your project, please consider citing it with
@misc{yang2024tidaldecodefastaccuratellm,
title={TidalDecode: Fast and Accurate LLM Decoding with Position Persistent Sparse Attention},
author={Lijie Yang and Zhihao Zhang and Zhuofu Chen and Zikun Li and Zhihao Jia},
year={2024},
eprint={2410.05076},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2410.05076},
}
Resources
- Codebase for reproducing all the results in the paper.