FlexFlow Serve
FlexFlow Serve is a low latency and high performance generative large language model (LLM) serving framework built on top of FlexFlow. The high computational and memory requirements of LLMs make it challenging to serve them quickly and cheaply. FlexFlow Serve is an open-source system that includes an automaticed tensor program compiler and an efficient distributed multi-GPU runtime for LLM inference accelaration. FlexFlow Serve provides the following key features:
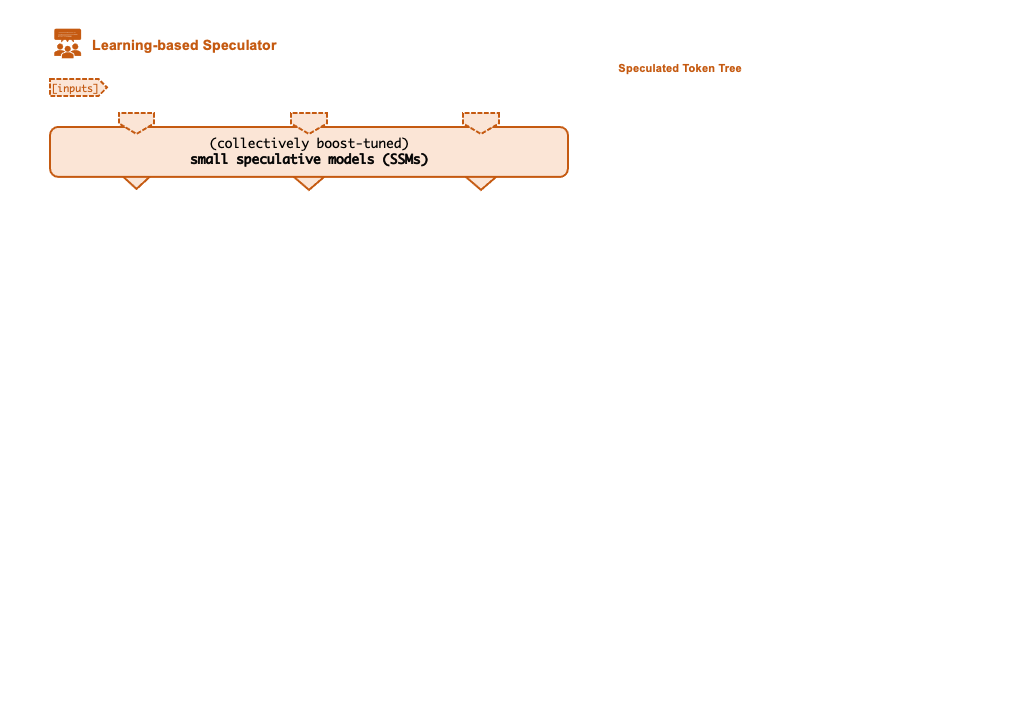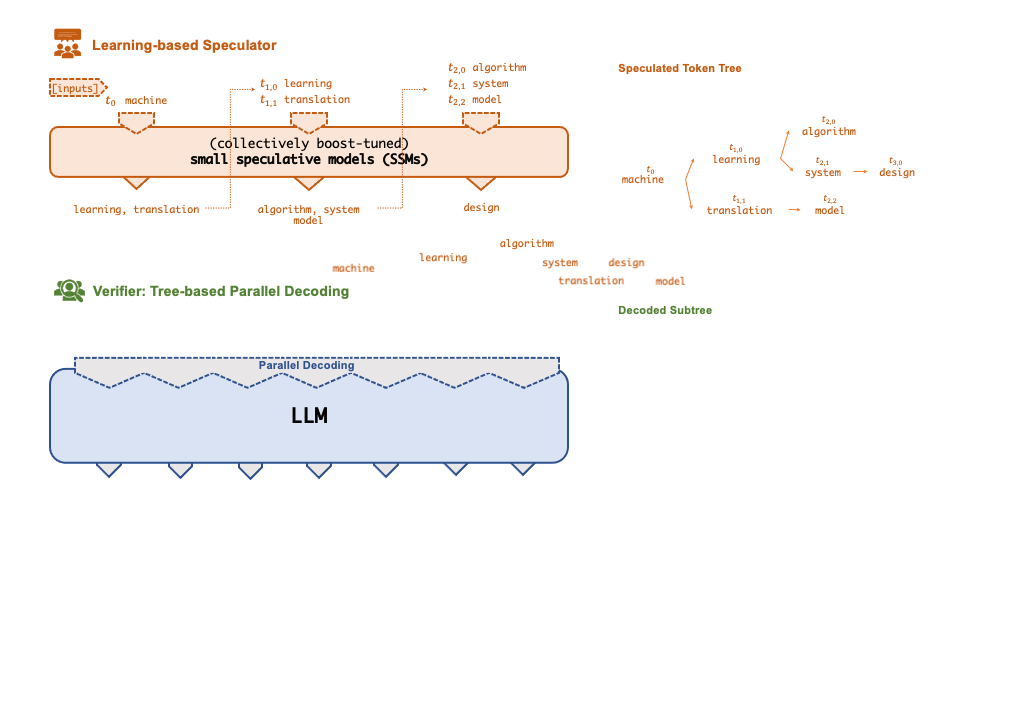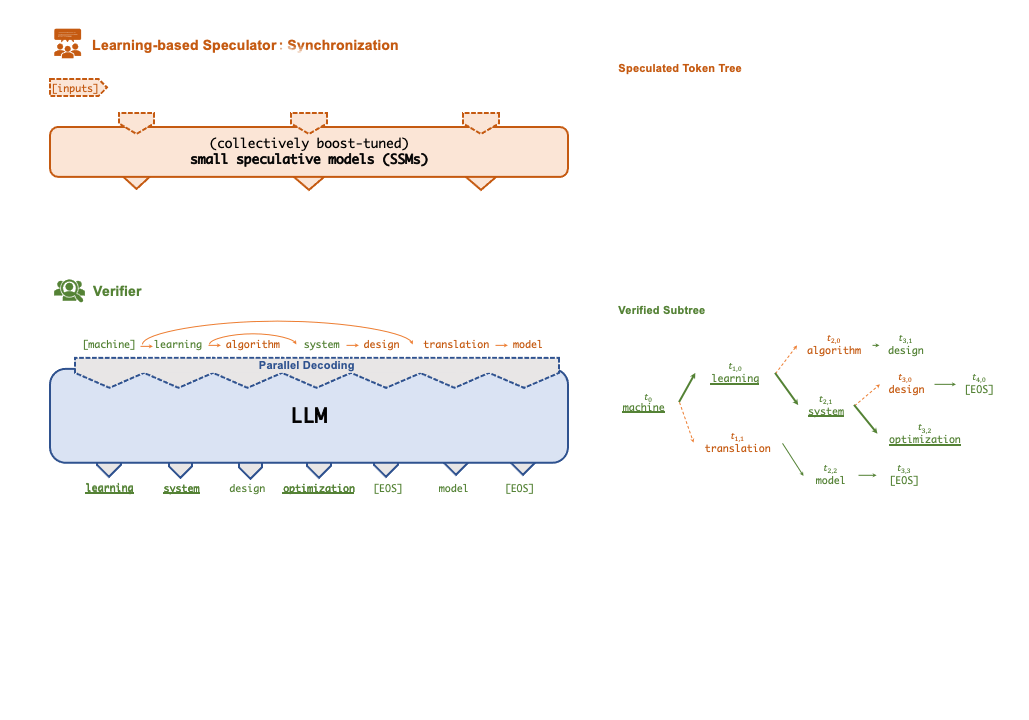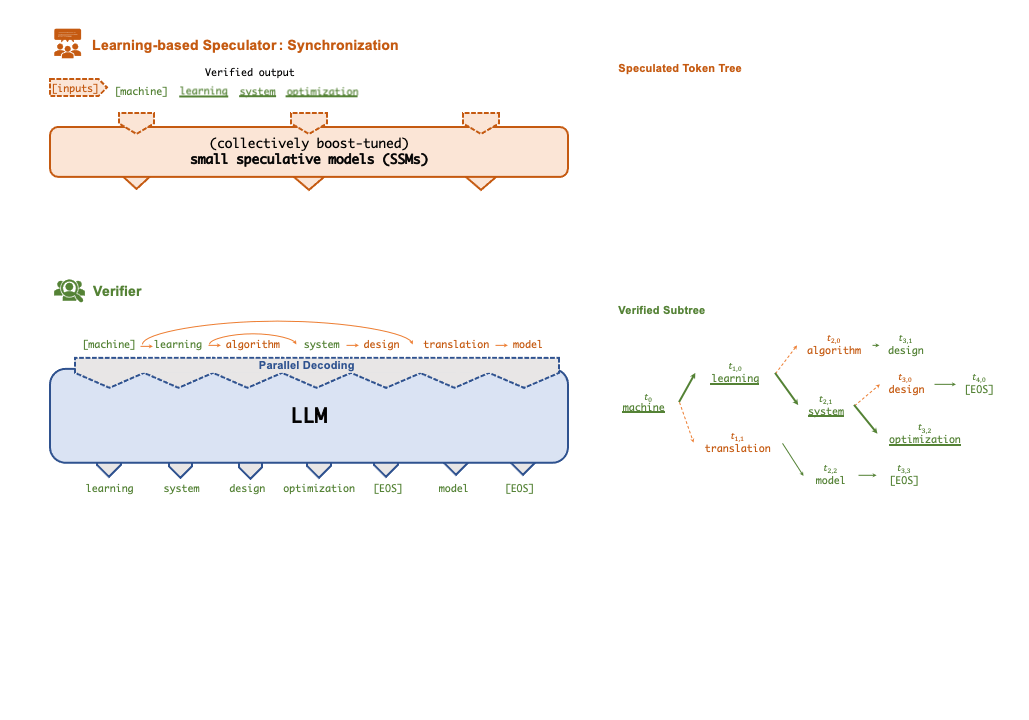
- Speculative Inference. FlexFlow Serve supports to accelerate LLM serving through tree-based speculative inference and token verfication. The key idea is to predict the the LLM’s outputs using small speculative models (SSMs) with fewer computational and memory overheads. The predictions are organized as a token tree and verified against the LLM’s output in parallel using a novel tree-based parallel decoding mechanism. By taking an LLM as a token tree verifier instead of an incremental decoder, FlexFlow Serve largely reduces the end-to-end inference latency and computational requirement for serving generative LLMs while provably preserving model quality.
-
CPU Offloading. FlexFlow Serve also offers offloading-based inference for running large models (e.g., llama-7B) on a single GPU. CPU offloading is a choice to save tensors in CPU memory, and only copy the tensor to GPU when doing calculation. Notice that now we selectively offload the largest weight tensors (weights tensor in Linear, Attention).
-
Quantization. FlexFlow Serve supports int4 and int8 quantization. The compressed tensors are stored on the CPU side. Once copied to the GPU, these tensors undergo decompression and conversion back to their original precision.
More information about FlexFlow Serve is available at https://flexflow.ai.
Publication
- Xupeng Miao*, Gabriele Oliaro*, Zhihao Zhang*, Xinhao Cheng*, Zeyu Wang, Rae Ying Yee Wong, Alan Zhu, Lijie Yang, Xiaoxiang Shi, Chunan Shi, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, Zhihao Jia. SpecInfer: Accelerating Generative Large Language Model Serving with Speculative Inference and Token Tree Verification. arXiv preprint arXiv:2305.09781, May 2023.